45 tf dataset get labels
Train and deploy a TensorFlow model - Azure Machine Learning In this article, learn how to run your TensorFlow training scripts at scale using Azure Machine Learning. This example trains and registers a TensorFlow model to classify handwritten digits using a deep neural network (DNN). Whether you're developing a TensorFlow model from the ground-up or you're bringing an existing model into the cloud, you ... stackoverflow.com › questions › 64687375Get labels from dataset when using tensorflow image_dataset ... Nov 04, 2020 · I am trying to add a confusion matrix, and I need to feed tensorflow.math.confusion_matrix() the test labels. My problem is that I cannot figure out how to access the labels from the dataset object created by tf.keras.preprocessing.image_dataset_from_directory() My images are organized in directories having the label as the name.
github.com › google-research › tf-slimGitHub - google-research/tf-slim Furthermore, TF-Slim's slim.stack operator allows a caller to repeatedly apply the same operation with different arguments to create a stack or tower of layers. slim.stack also creates a new tf.variable_scope for each operation created. For example, a simple way to create a Multi-Layer Perceptron (MLP):
Tf dataset get labels
Handwritten Digit Recognition with 98% Accuracy The MNIST Handwritten Digit Recognition Dataset contains 60,000 training and 10,000 testing labelled handwritten digit pictures. Each picture is 28 pixels in height and 28 pixels wide, for a total of 784 (28×28) pixels. Each pixel has a single pixel value associated with it. It indicates how bright or dark that pixel is (larger numbers ... how to extract label in processing image with tf.data from glob import glob import string alphabet = list(string.ascii_uppercase) idx = range(26) #create dict alphabet -> idx dict_alpha = dict(tuple(zip(alphabet, idx))) paths = glob('/content/drive/MyDrive/prom02/dataset/train/*.jpg') labels = [] for path in paths: alpha = path.split("/")[-1][0] labels.append(dict_alpha[alpha]) #split paths, labels using train_test_split sklearn train_ds = tf.data.Dataset.from_tensor_slices((paths, labels)) train_ds = train_ds.shuffle(len(paths)) def process ... Tensorflow time series classification with metadata: preprocessing ... Since you can build a data input pipeline with tf.data, which should be much faster, I am using now a python generator and the tf.data.Dataset.from_generator method. Basically my generator is given a list of all my…
Tf dataset get labels. Efficiently get an equal number of per class data point ... - GitHub [Info] TensorFlow: 2.6 Environment: Kaggle / Colab Accelerator: TPU. Current Behaviour? I am trying to get equal number of sample per class within a batch of data from tf.data API. With batch_size = 14 and sample_per_class = 3, I'm expecting to get as follows for num_classes = 5: Introduction to Recurrent Neural Networks with Keras and TensorFlow On Lines 26-28, we get the testing dataset and pre-process it. Line 37 will map the dataset to get the vectorized tokens and labels. On Lines 40-44, we evaluate the testing accuracy and the testing loss of the RNN model. Our model achieves 68.42% accuracy at inference! $ python inference.py [INFO] loading the pre-trained RNN model... Pandas DataFrame: drop() function - w3resource DataFrame - drop () function. The drop () function is used to drop specified labels from rows or columns. Remove rows or columns by specifying label names and corresponding axis, or by specifying directly index or column names. When using a multi-index, labels on different levels can be removed by specifying the level. The Annotated ResNet-50. Explaining how ResNet-50 works and why… | by ... (train_ds, valid_ds, test_ds), ds_info = tfds.load('stanford_dogs', split=['train', 'test[0%:10%]', 'test[10%:]'], shuffle_files=True, with_info=True, as_supervised=True) print("Dataset info: \n") print(f'Name: {ds_info.name}\n') print(f'Number of training samples : {ds_info.splits["train"].num_examples}\n') print(f'Number of test samples : {ds_info.splits["test"].num_examples}\n') print(f'Description : {ds_info.description}') tfds.show_examples(train_ds, ds_info) CLASS_TYPES = ds_info ...
Train deep learning Keras models - Azure Machine Learning It uses the popular MNIST dataset to classify handwritten digits using a deep neural network (DNN) built using the Keras Python library running on top of TensorFlow. Keras is a high-level neural network API capable of running top of other popular DNN frameworks to simplify development. With Azure Machine Learning, you can rapidly scale out ... ML lab 07-2: Meet MNIST Dataset : 네이버 블로그 import matplotlib. pyplot as plt import random # Get one and predict r = random.randint(0, mnist. test. num_examples - 1) print("Label: ", sess.run( tf.argmax( mnist. test. labels [ r : r + 1], 1))) print("Prediction: ", sess.run( tf.argmax( hypothesis, 1), feed_dict ={X: mnist. test. images [ r : r + 1]})) plt.imshow( mnist. test. images [ r : r + 1].reshape(28, 28), cmap ="Greys", interpolation ="nearest") plt.show() Sklearn | Feature Extraction with TF-IDF - GeeksforGeeks TF-IDF can be computed as tf * idf. Tf*Idf do not convert directly raw data into useful features. Firstly, it converts raw strings or dataset into vectors and each word has its own vector. Then we'll use a particular technique for retrieving the feature like Cosine Similarity which works on vectors, etc. Extracting labels and images from imagenet dataset using tensorflow ... #i = tf.expand_dims(i, axis=0) i = tf.keras.applications.mobilenet_v2.preprocess_input(i) return (i, label) train = ds['train'] val = ds['validation'] # Preprocess the images ds_train = train.map(resize_with_crop) ds_val = val.map(resize_with_crop) Now comes the filthy part. The way I extract the images and labels: label= [] img = [] counter = 0
scBasset: sequence-based modeling of single-cell ATAC-seq using ... To systematically compare scBasset and chromVAR on this task, we analyzed the 10x PBMC multiome dataset, in which TF expression measured in the RNA-seq can serve as a proxy for its motif's activity. Best practices for TensorFlow 1.x acceleration training on Amazon ... When you use the TensorFlow dataset API and distribute strategy together, the dataset object should be returned instead of features and labels in function input_fn. Usually, TensorFlow MirroredStrategy is slower than the tower method on CPU training, so we don't recommend using MirroredStrategy on a multi-CPU single host. Horovod machinelearningmastery.com › image-augmentationImage Augmentation with Keras Preprocessing Layers and tf.image If you run this code again at a later time, you will reuse the downloaded image. But the other way to load the downloaded images into a tf.data dataset is to use the image_dataset_from_directory() function. As you can see from the screen output above, the dataset is downloaded into the directory ~/tensorflow_datasets. If you look at the directory, you see the directory structure as follows: TensorFlow Estimator to CerebrasEstimator Finally, ensure that your model is running in Mixed Precision, using the tf.keras Mixed Precision policy. def model_fn(features, labels, mode=tf.estimator.ModeKeys.TRAIN, params=None): """ Model definition """ if params.get("mixed_precision", True): policy = Policy("infer_float32_vars") if mixed_precision else None tf.keras.backend.floatx("float16") logits = build_model(features, params) learning_rate = tf.constant(params["lr"]) if mode in (tf.estimator.ModeKeys.TRAIN, tf.estimator.ModeKeys.
Monitoring Oracle Database Appliance
A dataset of mentorship in bioscience with semantic and ... - Nature We map the Wikipedia labels into the same four categories of ethnicity listed before. Finally, we get a dataset with 720000 data points (black: 180000, Asian: 180000, Hispanic: 180000, white: 180000).
Transfer Function Tool (TFT) | DesignSafe-CI
keras.io › api › datasetsIMDB movie review sentiment classification dataset - Keras This is a dataset of 25,000 movies reviews from IMDB, labeled by sentiment (positive/negative). Reviews have been preprocessed, and each review is encoded as a list of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer "3" encodes the 3rd most frequent word in the data.
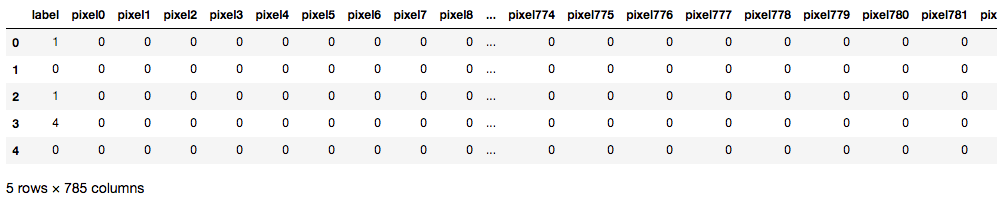
Kaggle’s Digit Recogniser using TensorFlow -LeNet Architecture
mne.Label — MNE 1.1.0 documentation The subset of tris used by the label. get_vertices_used (vertices = None) [source] # Get the source space's vertices inside the label. Parameters: vertices ndarray of int, shape (n_vertices,) | None. The set of vertices to compare the label to. If None, equals to np.arange(10242). Defaults to None. Returns: label_verts ndarray of in, shape (n_label_vertices,)

Analyze tf.data performance with the TF Profiler | TensorFlow Core
datasets · PyPI With a simple command like squad_dataset = load_dataset("squad"), get any of these datasets ready to use in a dataloader for training/evaluating a ML model ... the user-facing dataset object of 🤗 Datasets is not a tf.data.Dataset but a built-in framework-agnostic dataset class with methods inspired by what we like in tf.data (like a map ...

Training MNIST dataset by TensorFlow | Research Blog
How to apply KNN algorithm using tf - ProjectPro # manhattan distance manht_distance = tf.reduce_sum(tf.abs(tf.subtract(x_new_train, tf.expand_dims(x_new_test, 1))), axis=2) # nearest k points _, top_k_indices = tf.nn.top_k(tf.negative(manht_distance), k=k) top_k_labels = tf.gather(y_new_train, top_k_indices) predictions_sumup = tf.reduce_sum(top_k_labels, axis=1) make_prediction = tf.argmax(predictions_sumup, axis=1)

Importing my own dataset for the Nengo Model - General Discussion - Nengo forum
› guide › datatf.data: Build TensorFlow input pipelines | TensorFlow Core Jun 09, 2022 · The tf.data API enables you to build complex input pipelines from simple, reusable pieces. For example, the pipeline for an image model might aggregate data from files in a distributed file system, apply random perturbations to each image, and merge randomly selected images into a batch for training.
TFORMer - Barcode Label Printing Software | heise Download
tfds.load | TensorFlow Datasets bool, if True, the returned tf.data.Dataset will have a 2-tuple structure (input, label) according to builder.info.supervised_keys. If False, the default, the returned tf.data.Dataset will have a dictionary with all the features. decoders: Nested dict of Decoder objects which allow to customize the decoding. The structure should match the feature structure, but only customized feature keys need to be present.

python - Why does shuffling sequences of data in tf.keras.dataset affect the order of sequences ...
Software Documentation (Version 1.4.0) - Cerebras Returns a tf.data.Dataset that yields tensor pairs in the predefined format: tensor with features and tensor with labeles. Any params passed to the CerebrasEstimator are passed on to the input_fn and to the model_fn. when the CerebrasEstimator calls the input_fn. The input_fn should return a tf.data.Dataset (see Dataset API for documentation).

Tutorials « webcose « Page 2
TensorFlow 2 Tutorial: Get Started in Deep Learning with tf.keras In this tutorial, you will discover a step-by-step guide to developing deep learning models in TensorFlow using the tf.keras API. After completing this tutorial, you will know: The difference between Keras and tf.keras and how to install and confirm TensorFlow is working. The 5-step life-cycle of tf.keras models and how to use the sequential ...

TFS Build - get source code by label issues - Stack Overflow
Train Custom Data · ultralytics/yolov5 Wiki · GitHub 1. Create Dataset. YOLOv5 models must be trained on labelled data in order to learn classes of objects in that data. There are two options for creating your dataset before you start training: Use Roboflow to label, prepare, and host your custom data automatically in YOLO format 🚀 NEW (click to expand) 1.1 Collect Images. Your model will ...

Implementing Tags in a Database?? – davelevy.info
Vertex AI Workbench: Train a TensorFlow model with data from BigQuery Use the above function to create two tf.data.Datasets, one for training and one for validation. You might see some warnings, but you can safely ignore them. train_dataset = df_to_dataset(train_data, 'duration') validation_dataset = df_to_dataset(val_data, 'duration') You'll use the following preprocessing layers in the model:

Implementing a CNN for Human Activity Recognition in Tensorflow - Aaqib Saeed
How to get tensorflow BERT transformer to predict? My code is below. Code: from datasets import load_dataset from transformers import AutoTokenizer from transformers import DefaultDataCollator import tensorflow as tf # going to train and test on yelp review dataset dataset = load_dataset ("yelp_review_full") print (dataset ["train"] [10]) tokenizer = AutoTokenizer.from_pretrained ("bert-base ...

New APIs in Tensorflow - Speaker Deck
Training tree-based models with TensorFlow in just a few lines of code And finally we will convert the dataset into tf.data format. This is a high-performance format that is used by TensorFlow to train models more efficiently, and with TensorFlow Decision Forests, you can convert your dataset to this format with one line of code: train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label="class")

TensorFlow Classify Images of Cats and Dogs by Using Transfer Learning | by Nutan | Medium
Hugging Face's TensorFlow Philosophy Simple - wrap it with a tf.data.Dataset and all our problems are solved - data is loaded on-the-fly, and padding is applied only to batches rather than the whole dataset, which means that we need way fewer padding tokens: tf_dataset = model.prepare_tf_dataset( dataset, batch_size= 16, shuffle= True) model.fit(tf_dataset)
Getting Started
Classify structured data using Keras preprocessing layers def df_to_dataset(dataframe, shuffle=True, batch_size=32): df = dataframe.copy() labels = df.pop('target') df = {key: value[:,tf.newaxis] for key, value in dataframe.items()} ds = tf.data.Dataset.from_tensor_slices((dict(df), labels)) if shuffle: ds = ds.shuffle(buffer_size=len(dataframe)) ds = ds.batch(batch_size) ds = ds.prefetch(batch_size) return ds

Simple Word Embedding for Natural Language Processing | by Srinivas Chakravarthy | Towards Data ...
› api_docs › pythontf.data.Dataset | TensorFlow v2.9.1 Overview; LogicalDevice; LogicalDeviceConfiguration; PhysicalDevice; experimental_connect_to_cluster; experimental_connect_to_host; experimental_functions_run_eagerly
Post a Comment for "45 tf dataset get labels"